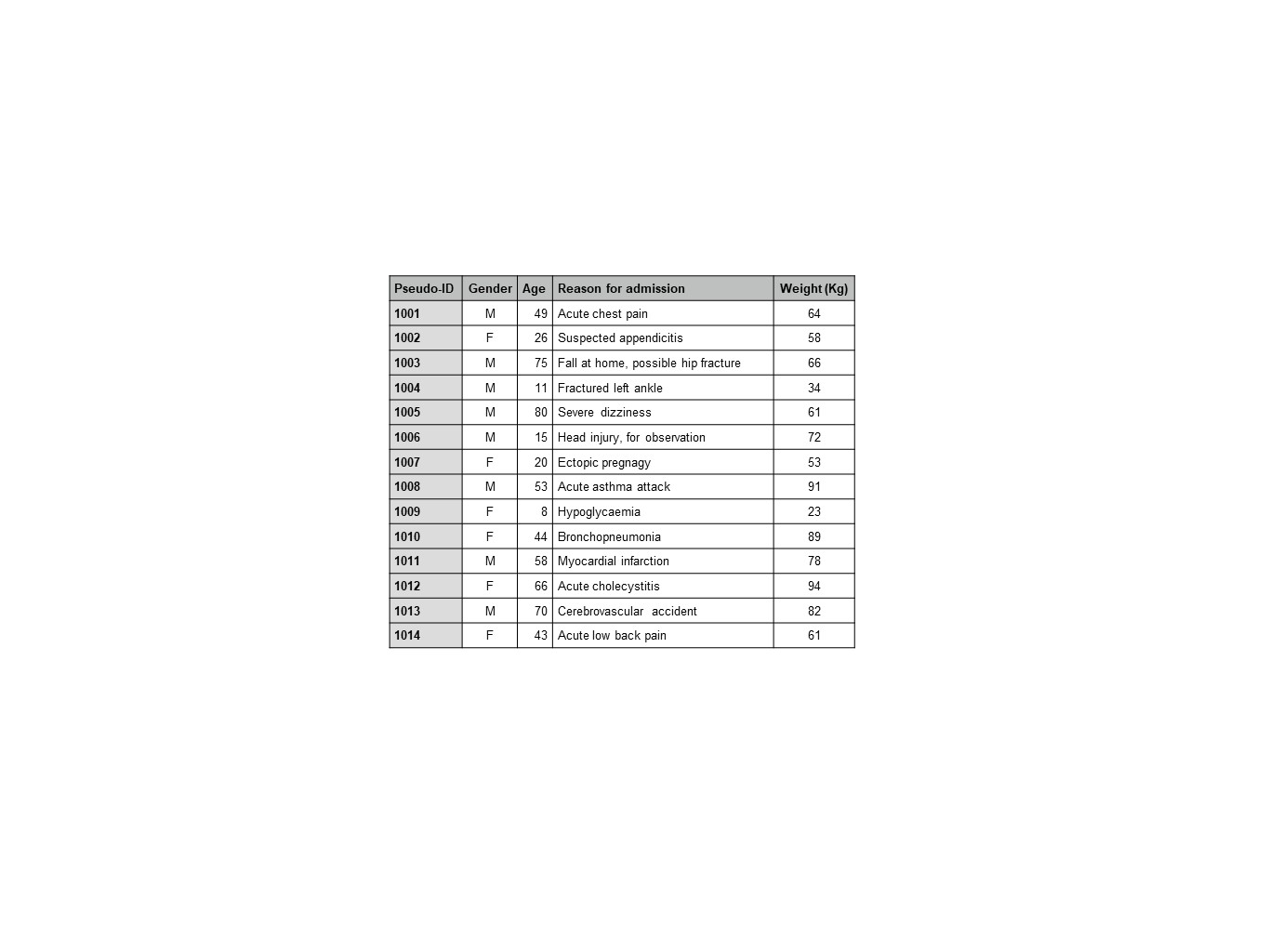
Anonymisation of health data
It is very common for health data to be anonymised before it is released to a research organisation.
Anonymisation is a formal technique in which all of the information about an individual that could identify the person is removed. This includes names, contact details, national identity number, hospital number, laboratory number etc. This removal greatly reduces the chance of any person being recognised from a health database.
However, this action is not enough as health data can include unusual information patterns that give away who a person is even if their actual identity is not present. Anonymisation must include additional steps to mask such information. For example, dates such as date of birth, date of an operation or clinic appointment are often “rounded” to the nearest year or five-year band. A person’s occupation may be changed from a specific kind of job to a job category. Geographic locations such as a home address or place of work may be “rounded” to a city or country. Additional protection arises when data are combined from multiple sources. For example, when all the data about patients with a particular cancer are combined from many hospitals within a city or country, so the research team do not know which hospital any of the data have come from.
Letters and reports written as documents need extra care. It is very hard to anonymise long paragraphs of text fully, because incidental remarks may give away who a person is. Letters and reports are not normally provided to research organisations for this reason.
Modern computerised language analysis software can extract useful medical facts from the text. These facts can be added to the research data without needing to release the actual documents the facts come from.
There are guidelines available to healthcare and research organisations about how they should anonymise to a high standard.
When anonymised data is released to a research organisation, they should have no way of tracing back to who any individuals are.